Moovie 做的是聚合搜索,一次搜索会同时请求多个资源站的 API,把结果汇总展示给用户。这就带来了一个问题:同一个影片,不同资源站返回的播放链接,速度差异巨大。有的源秒开,有的源转圈十几秒才能播放,甚至有些链接根本就是失效的。
用户面对一堆不同来源的资源,只能一个一个点进去试,体验很差。所以需要一种机制,自动给每个资源链接评估出一个"速度分",好用的排前面,不好用的排后面。
早期方案
最开始的做法很直观:用户点进播放页时,用 JS 加载 m3u8 文件里的第一个 ts 分片,记录下载耗时,当作这个源的速度指标。
这个方案有两个硬伤:
- 测完就扔。速度数据存在浏览器内存里,页面一关就没了,无法持久化保存,也就没法用来做搜索结果排序。
- 不够准确。只测了第一个 ts 分片的下载速度,不代表实际播放体验。有些源第一个分片秒下,但后续分片卡得要命;有些源需要等 HLS manifest 解析完才能开始播放,这部分时间完全没被算进去。
现在的方案
既然"主动测速"不靠谱,那就换个思路——不测了,直接统计真实播放行为。
用户每次播放视频,播放器本身就知道两件事:加载了多久才开始播放,以及最终有没有播放成功。把这两个数据上报到服务端,日积月累就能得到每个资源的真实质量数据。
本质上就是把"每次播放"变成了一次"投票",投出这个源的速度和可用性。
数据采集
播放器初始化时记录一个起始时间,然后设置一个 30 秒超时保底。接下来在合适的时机判定成功或失败:
- HLS 视频:m3u8 分片列表解析完成,说明可以开始播放了,算成功。
- 通用回退:浏览器触发 canplay 事件,算成功。
- 播放出错:触发 error 事件,算失败。
- 超时:30 秒内没有任何成功事件触发,自动判定失败。
成功时上报耗时毫秒数,失败时上报失败状态。为了防止用户反复刷新页面导致重复上报,每次页面加载只允许上报一次。
增量平均算法
数据上报到服务端之后,关键问题是:怎么更新平均速度?
最朴素的做法是把所有历史记录查出来重新算一遍均值,但这显然太浪费了。实际上只需要一个增量公式:
新平均值 = (旧平均值 × 旧样本数 + 本次耗时) / (旧样本数 + 1)
举个例子。假设某个资源当前的平均加载速度是 2000ms,累计播放了 1 次。现在第 2 个用户播放,耗时 1000ms,那么新的平均值就是 (2000 × 1 + 1000) / 2 = 1500ms。第 3 个用户播放耗时 3000ms,平均值变成 (1500 × 2 + 3000) / 3 = 2000ms。
这个算法的好处是:数据库里只需要存三个整数——平均耗时、成功次数、失败次数。每次上报都是一条 SQL 直接更新,不需要先查再算,也不需要保存任何历史记录。
失败的上报更简单,只需要给失败次数加一就行了。
成功率
成功率不是提前存好的,而是读取时实时算:(成功次数 - 失败次数) / 成功率次数 × 100%。比如 10 次播放中 2 次失败,成功率就是 80%。
数据怎么用
搜索结果排序
搜索结果默认按平均加载速度排序,速度快的排前面,没有速度数据的源排在后面。用户不需要自己试错,好用的源自然浮到顶部。
速度标签
搜索结果卡片上会展示一个直观的速度标识:绿点"极速"表示平均 1 秒内加载完成,橙点"正常"表示 1 到 3 秒,红点"较慢"表示超过 3 秒。
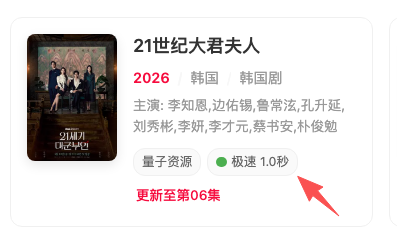
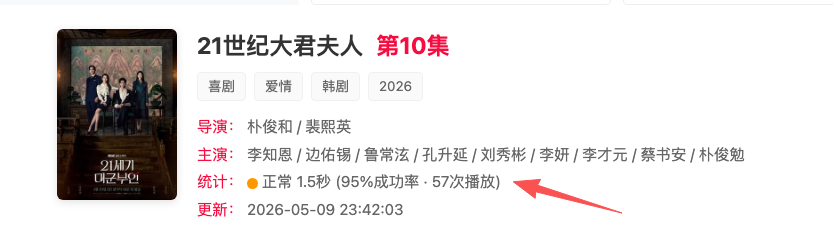
播放页会展示更详细的数据,包括成功率和累计播放次数,比如"95% 成功率 · 57 次播放"。用户一眼就能判断这个源靠不靠谱。
为什么这样做
- 众包采集。不需要自己维护测速服务,每个用户的正常播放行为就是一个数据样本。用的人越多,数据越准。
- 零额外开销。不发送额外的网络请求,只是在播放器已有的生命周期里顺手上报一条数据。
- 实时反馈。某个资源站挂了,失败次数会迅速上升,成功率下降,搜索排名自然降低。恢复后新数据会慢慢把均值拉回来。
- 存储成本极低。每个资源只需 3 个整数字段,增量更新,不需要存历史记录。
评论 2 条
网站改版了啊,好久没来,还以为进错地方了,看这新闻更新频率也低好多了
↳ 回复 #1 @littleboyzt
对,改版有一段时间了,最近在搞新项目更新频率少了 😂